研究概述
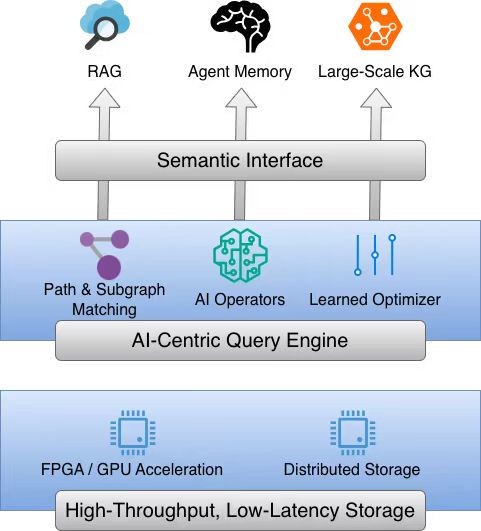
AI时代的数据库系统
当前,随着人工智能技术向纵深发展,数据管理的应用需求正经历一场深刻的范式转移:从传统的事务处理日益聚焦于实体间复杂的语义关联性。在这一趋势下,图数据库凭借其自然刻画高维关联数据的拓扑优势,已成为支撑检索增强生成(RAG)、智能体记忆(Agent Memory)及大规模知识图谱等AI核心应用的关键基石。然而,传统数据库架构难以适应AI时代的新挑战,主要体现在AI模型与数据库模式间的语义交互鸿沟,内核层对语义算子缺乏原生支持且难以将其纳入查询优化全流程,同时在面对极大规模数据时,现有的存储与查询机制也面临严峻的性能瓶颈。
针对上述挑战,本研究致力于构建一套深度融合AI技术的下一代图数据库系统。我们将首先构建面向AI的语义层,旨在消除模型理解数据的障碍。在核心的查询与优化层面,本研究提出一种新型融合查询优化框架,该框架不仅支持路径游走与子图匹配相结合的灵活查询定义,更通过将AI算子内嵌至执行引擎,采用传统规则与前沿的学习型优化器(Learned Optimizer)相结合的策略,实现查询效率的质变。此外,底层架构将依托分布式存储引擎与软硬件协同设计,确保系统在处理海量数据时具备高吞吐与低延迟能力,从而为AI时代的智能应用提供坚实、高效的数据底座。
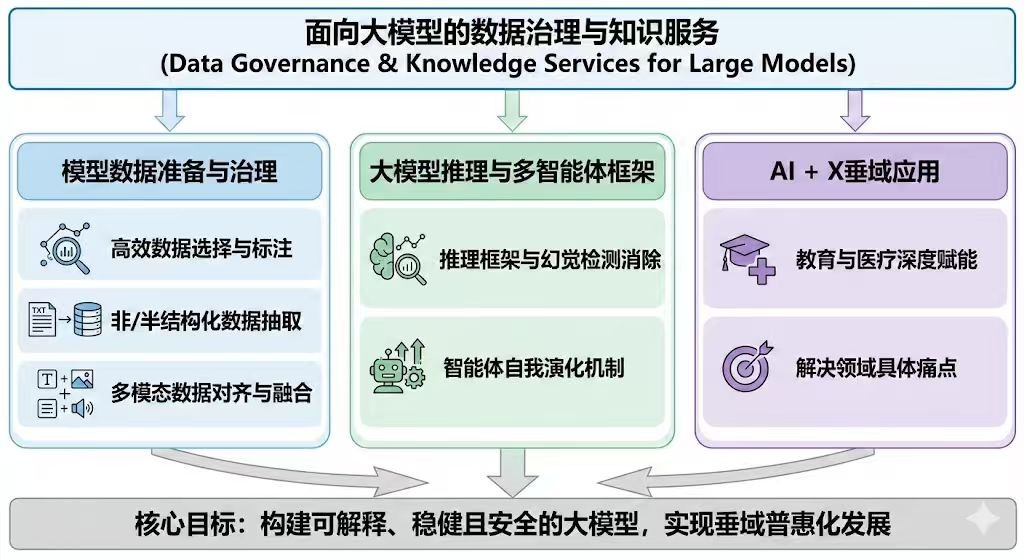
面向大模型的数据治理与服务
当前,数据驱动(Data-driven)是大模型研究的主要范式。大模型的构建与应用涉及海量数据,这些数据存在标注成本高、非结构化与多模态数据管理困难等问题,同时大模型的可信与稳健性以及应用落地的公平性与普惠性也面临诸多挑战。我们致力于通过协同优化数据治理质量与AI基础设施效能,构建可解释、稳健且安全的大模型推理机制,以实现垂域智能化应用的深度赋能与普惠化发展。具体而言,我们开展以下研究工作:
模型数据准备与治理:在面向AI的数据准备方面,我们研究如何更高效地选择具有代表性的数据进行标注,降低标注成本的同时提高数据标注的质量。对于结构化数据抽取,我们致力于开发更先进的技术,从海量的非结构化和半结构化数据中准确提取有价值的信息,将其转化为结构化数据,为大模型的训练提供高质量的数据支撑。在多模态数据对齐领域,我们研究如何将不同模态的数据进行有效的对齐和融合,充分利用多模态信息的互补性,提升大模型的感知和理解能力。
大模型推理与多智能体框架:针对大模型推理可解释的需求,我们开展推理框架与幻觉检测、消除技术的研究。通过深入分析大模型的推理过程,构建内部推理图谱,以便清晰地呈现推理路径。同时,运用先进的算法和技术手段,对可能出现的幻觉现象进行精准检测及消除,提升大模型推理的可信度与可解释性。此外,为使大模型具备更好的适应性和自我进化能力,我们探索智能体自我演化(Self-Evolve)机制,采用自底向上规划和长短期记忆机制等方法,让智能体在与环境的交互中不断学习和优化。
AI + X垂域应用:基于我们在自然语言处理、大模型方面的综合研究成果,结合数据库系统、数据治理等基础研究,将大模型技术应用于教育和医疗等垂域,解决领域具体痛点(如罕见病诊疗等问题),为这些领域带来深度赋能。
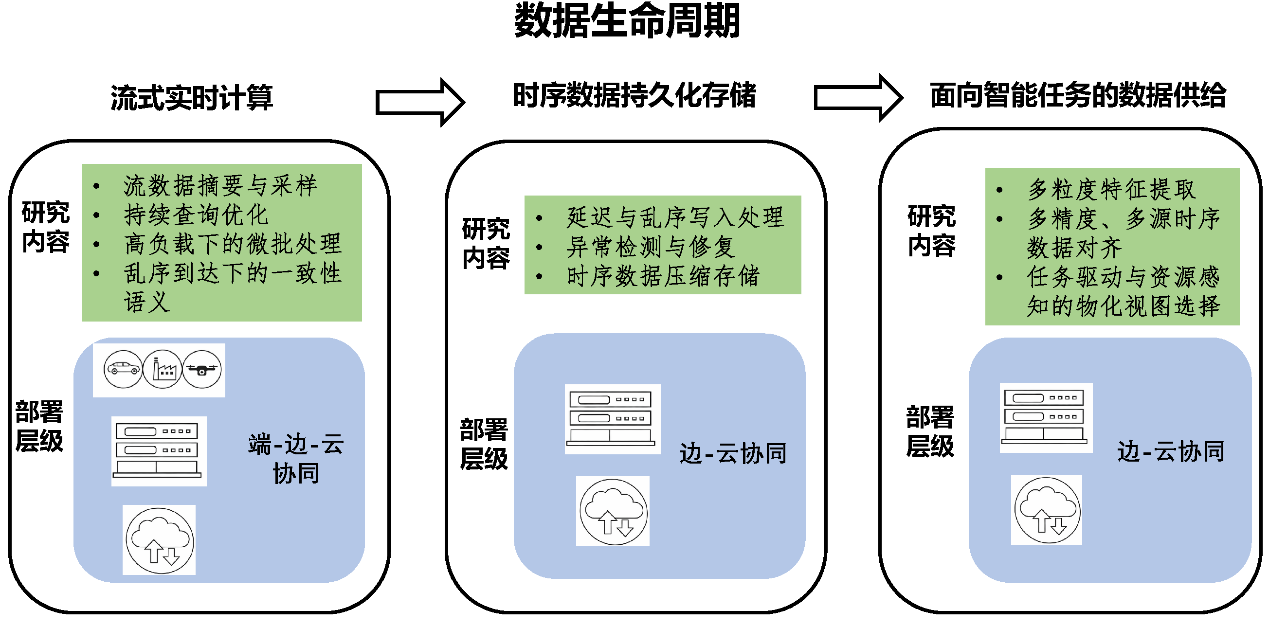
流数据与时序数据管理
在制造强国战略持续推进的背景下,工业物联网、智慧城市与智慧医疗等新一代信息系统加速部署,海量感知设备持续产生高频、多源、异构的流数据。流数据通常以时间为天然组织维度,经过在线处理与持久化存储后,沉淀为结构化的时序数据。流数据与时序数据管理是同一数据生命周期中前后衔接的两个关键阶段:前者关注数据在到达过程中的实时计算与增量处理,后者关注数据在持久化后的结构化组织、质量保障与分析支持。
流数据“边到达、边计算”的处理模式,使其难以依赖传统离线集中式分析;同时,实际系统普遍采用端侧—边缘—云服务器的分层协同架构,不同层级在计算资源、存储能力与可容忍延迟方面存在显著差异。数据在端侧产生、在边缘侧进行低延迟处理、在云侧完成规模化存储与复杂分析,形成了从流数据处理到时序数据管理的连续演进过程。在此背景下,如何在资源受限与高并发约束下,实现流数据的高效处理,并在此基础上保障时序数据的质量与可用性,成为支撑智能应用的核心基础问题。
围绕流数据与时序数据的全生命周期,本研究拟构建“流式实时计算—时序数据持久化存储—面向智能任务的数据供给”的一体化技术体系。在流式实时计算阶段,研究流数据摘要与采样算法以及复杂持续查询优化机制,重点探索高更新强度场景下实时处理与微批处理的协同机制,在保证低延迟响应的同时提升整体吞吐效率,并支持乱序到达场景下的一致性语义保障。在时序数据持久化阶段,关注时序数据的高效写入机制、存储结构优化与数据质量保障,系统研究延迟与乱序数据的写入策略、异常数据识别与纠正机制,以及时序数据压缩与存储优化方法,在任务需求与资源约束动态变化条件下,实现数据质量与处理代价之间的自适应平衡。进一步,在面向智能任务的数据供给阶段,构建面向智能分析的多粒度特征提取与多源时序数据对齐机制,设计任务驱动与资源感知相结合的物化视图选择与维护策略,为上层智能分析与决策系统提供高质量、可调度、可演化的数据视图支持。
通过上述分层协同与能力递进,本研究旨在形成覆盖端—边—云架构的流数据-时序数据管理与分析方法体系,为大规模信息系统的稳定运行与智能应用的持续演进提供坚实的数据基础。